
Audio Framing with Librosa (Python)
Written on July 13, 2020
This post provides a basic introduction to start with using Librosa audio data processing. Librosa supports lots of audio codecs. Although .wav(lossless) is widely used when audio data analysis is concerned. Once you have successfully installed and imported libROSA in your jupyter notebook.
Glossary
| Term | Meaning |
|---|---|
| sr(sample_rate) | Sampling rate, indicating how many sample points are sampled per second |
| hop_length | Stride; frame shift corresponds to stride in convolution; continuous frame segmentation length |
| overlapping | Overlapping part of two consecutive frames |
| n_fft | Window size; n_fft = hop_length+overlapping |
| MFCC | Mel Frequency Ceptrum Coeffient |
Windowing Process in Audio Processing
1. Audio Framing
Use window functions to divide audio of different lengths into audio segments of the same size. (The default sampling rate is 22050Hz).
Generally, there are two description methods:
Method 1 (Frame description method):
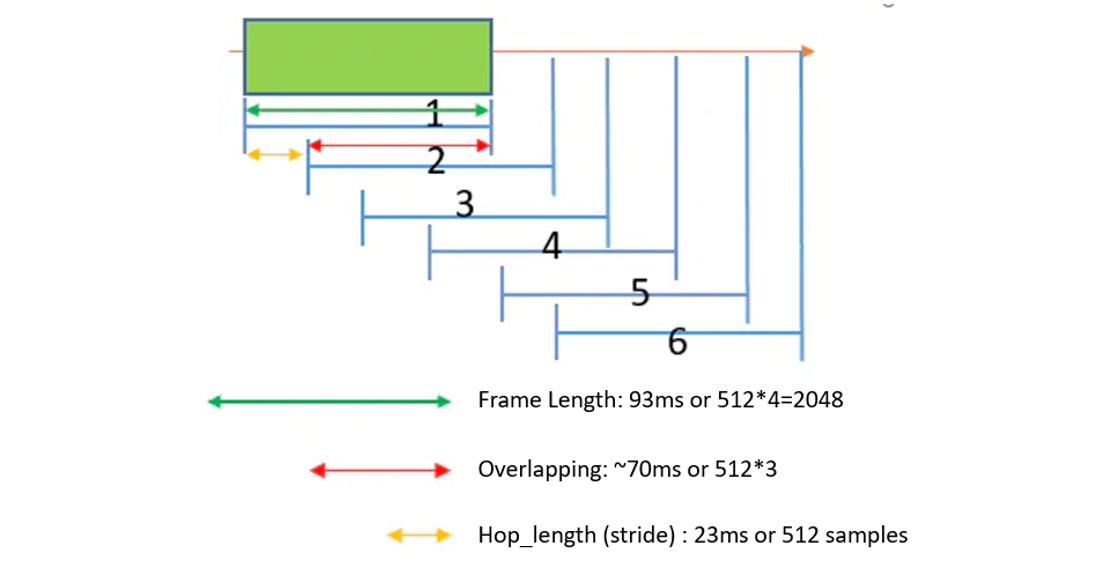
- Uses 2048 ((2048 1000ms)/22050=93ms) sampling points,
- and the front and back windows overlap 512 3 sampling points.
Method 2 ( Time description method):
- Use a frame length of 93ms, a frame shift of 23ms (hop_length),
- and a periodic Hann window to frame the voice.
For example: the following picture divides an audio into 6 equal audio segments through a sliding window:
Common operations
# window_size, the overlapping part of the continuous window is window_size/2
def windows(audio, window_size):
start = 0
while start < len(audio):
#len(audio) is the total number of sample points for an audio file.
Yield start, start + window_size #Retrieve the sample point index index of length window_size
Start += (window_size / 2) #Calculate the starting position of the next segment
2. Calculate the melspectrogram of each frame.
Signal = audio[0,2048] #(audio[0,2048] represents the segment 1 of the segment in the graph
#Next row calculates the 64-order mel spectrum of the segmentation audio[0,2048]
#sr represents the sampling rate, which indicates how many sample points are sampled in one second.
#n_fft indicates the number of consecutive sample points used by the short-time Fourier transform
#hop_length: Number of overlapping sample points of two consecutive Fourier changes
melspec = librosa.feature.melspectrogram(signal, sr=22050,
n_fft=2048,
hop_length=512,
n_mels = 64)
# Splits an original audio file into equal-sized segments.
# Then calculate the og mel_sepctrogram for each fragment.
for (start,end) in windows(audio,window_size):
#(1) This is to use the size window_size for audio files of different sizes.
#stride=window_size/2 The window is divided into time segments of equal size.
#(2) Calculate the log mel_sepctrogram of each segment.
If(end<= len(audio)): #The last sample point of a window is not enough
Signal = audio[start:end] # Segmented audio frames (1, 2, 3, 4, 5, 6 in the figure)
Melspec = librosa.feature.melspectrogram(signal, n_mels = 64) #Calculate the mel spectrum of each segment
Logspec = librosa.logamplitude(melspec)#calculate log mel spectrum
References
Reference materials: